





Conjuntos de datos de desarrollo y evaluación
Este estudio utilizó un conjunto de datos de imágenes de mipografía de trabajos publicados anteriormente.20 Junto con la información demográfica del sujeto correspondiente para desarrollar y evaluar un algoritmo de aprendizaje profundo.
Reclutamiento y fotografía
Sujetos humanos adultos (edad \ (\ Energia General \) 18 años) de la Universidad de California (UC), campus de Berkeley y la comunidad circundante para realizar evaluaciones de la superficie ocular en una sola visita en el Centro de Investigación Clínica de UC Berkeley de 2012 a 2017. Los sujetos elegibles estaban libres de contraindicaciones para los ojos. mepografía, actualmente no toma medicamentos que tengan efectos en el ojo anterior o accesorio, y no tiene antecedentes de cirugía ocular. El protocolo de investigación se adhirió a los principios de la Declaración de Helsinki y fue aprobado por la Junta de Revisión Institucional (Comité para la Protección de Individuos de UC Berkeley). Se obtuvo el consentimiento informado de todos los sujetos después de que se les informara de los objetivos, procedimientos, riesgos y beneficios potenciales del estudio. Las imágenes de meibografía de los párpados superiores de ambos ojos se tomaron con un OCULUS Keratograph 5M (OCULUS, Arlington, WA), un instrumento clínico que usa luz infrarroja a una longitud de onda de 880 nm para obtener imágenes de la glándula de Meibomio.27. Durante la sesión de fotos, la luz ambiental estaba apagada con la cabeza del objetivo apoyada en la mentonera y el dispositivo de correa para la frente. Se recopilaron y clasificaron previamente un total de 750 imágenes para excluir las imágenes que no capturaban todo el párpado superior (61 imágenes o el 8,90 %); Las 689 imágenes restantes se utilizaron en el análisis.
datos demográficos
Los datos demográficos de los sujetos se documentaron durante la visita. En este trabajo se estudiaron tres características demográficas: edad, género y raza. Figura 1. Presenta gráficos que representan las distribuciones de estos rasgos demográficos. La falta de suficientes sujetos para ciertas etnias para un entrenamiento adecuado del modelo nos permitió hacer predicciones precisas para nuestros dos grupos más grandes: caucásicos y asiáticos. Esto eleva el número total de imágenes utilizadas para la predicción racial a 421, mientras que las 689 imágenes se utilizaron para predecir la edad y el sexo.
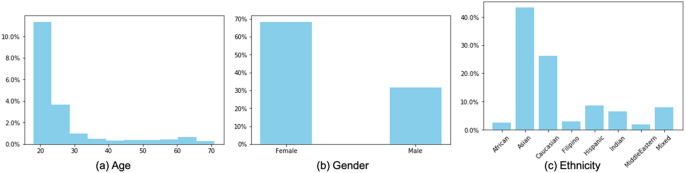
Histogramas (en porcentaje) de las características demográficas de nuestro conjunto de datos Mipography.
características morfológicas
El desarrollo de un modelo de aprendizaje profundo interpretable para predecir la demografía requiere características morfológicas como la longitud de la glándula y el alias como fuentes de datos. Se identificaron ocho características morfológicas para cada imagen mipográfica como en nuestro trabajo anterior: número de glándulas, densidad de glándulas, porcentaje de área de atrofia de glándulas, variación local de glándulas, longitud de glándulas (mm), ancho de glándulas (mm), desviación de glándulas y porcentaje. de glándulas fantasmas20. Los gráficos de estas características morfológicas se muestran en la Figura 2.
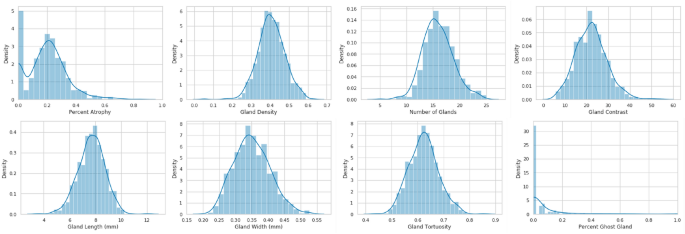
Histogramas de densidad y densidad de rasgos morfológicos a partir de metagrafías.
división de datos
Las imágenes de meibografía se dividieron en dos subgrupos exclusivos para el entrenamiento y evaluación del modelo de aprendizaje profundo. Las imágenes recopiladas de los años 2015 a 2017 se combinaron para formar el grupo de desarrollo, mientras que las imágenes de 2012 a 2013 se combinaron para formar el grupo de evaluación. Todas las imágenes fueron tomadas con el mismo instrumento bajo el mismo protocolo. El conjunto de desarrollo se dividió aleatoriamente en dos subgrupos para el entrenamiento y la validación del modelo. Específicamente, el conjunto de validación se utilizó para ajustar los hiperparámetros del modelo (por ejemplo, la tasa de aprendizaje típica) del modelo entrenado al conjunto de entrenamiento. El conjunto de evaluación se utilizó para evaluar y probar el rendimiento del modelo. Las características demográficas objetivas divididas entre los conjuntos de datos de desarrollo y evaluación se presentan en la Tabla 1. Los diferentes subgrupos tenían distribuciones de características demográficas similares, de modo que se minimizó el cambio de distribución entre los grupos de capacitación y evaluación.
Diseño y entrenamiento de algoritmos.
El objetivo general es diseñar un modelo de aprendizaje profundo interpretable que pueda predecir la demografía de los sujetos. La interpretación requiere que el modelo sea capaz de identificar las características morfológicas más probables que utiliza el algoritmo para predecir las características demográficas de un sujeto directamente a partir de su mipografía. Se diseñó un modelo de dos etapas con un modelo de aprendizaje de rasgos de primera etapa para identificar y cuantificar las características morfológicas de las imágenes meibográficas de entrada, y un modelo de predicción demográfica de segunda etapa para predecir las características demográficas del sujeto a partir de la meibografía de primera etapa y las características morfológicas correspondientes. caracteristicas. La figura 3 muestra la canalización general.
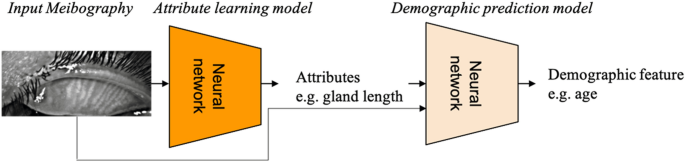
La canalización general de un modelo de aprendizaje profundo interpretable para predecir datos demográficos a partir de imágenes.
función de aprendizaje profundo
En la primera etapa, se desarrolla un modelo de aprendizaje profundo para predecir y determinar las características morfológicas de una meibografía particular (primera parte de la Fig. 3). El objetivo principal de un modelo de aprendizaje de rasgos es proporcionar rangos valiosos en lugar de valores exactos de rasgos morfológicos para las predicciones demográficas finales. Hay dos razones principales para esto: (1) Predecir rangos de valores aproximados es más fácil que predecir valores exactos de un modelo de aprendizaje profundo, especialmente porque el conjunto de datos (un total de 689 imágenes) no era lo suficientemente grande para aprender los valores de finos rasgos morfológicos. (ii) La predicción de los rasgos morfológicos fue un resultado intermedio, con el objetivo principal de explicar las relaciones entre los rasgos demográficos y morfológicos. Los rangos de valores predictivos son suficientes para esto. Por ejemplo, sería aceptable predecir el sexo para encontrar que las mujeres muestran una alta probabilidad de tener más de 15 glándulas en lugar de una alta probabilidad de tener exactamente 16 glándulas. Por lo tanto, nuestro modelo de aprendizaje profundo de primera etapa predice que las características morfológicas se encuentran dentro de rangos ordinales (o, en el caso del porcentaje de glándula fantasma, bicapas).
El modelo de aprendizaje de rasgos morfológicos predice específicamente un nivel de triplete en lugar del valor numérico exacto de cada característica morfológica. Como se muestra en la Figura 4, el modelo predice que cada valor de característica morfológica cae por debajo de él \(\mu – \sigma\) (nivel 1), entre \(\mu – \sigma\) Y el \(\mu + \sigma\) (Nivel 2) o superior \(\mu + \sigma\) (nivel 3), donde \(\mes\) Y el \(\sigma\) Consulte la media y la desviación estándar de la característica morfológica de la distribución del valor esperado. La Tabla 2 proporciona \(\mes\) Y el \(\sigma\) Para todas las características morfológicas examinadas. En el caso del porcentaje de glándulas fantasma, el 77,1% de las imágenes (o 531 imágenes) no contenían glándulas fantasma. Por lo tanto, para la predicción porcentual se utilizó una categoría binaria (porcentaje de glándulas fantasma = 0 o > 0).
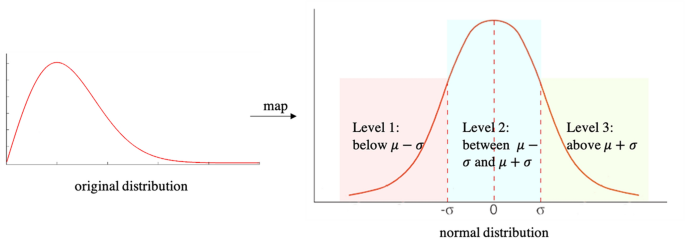
Establezca la distribución del modelo de aprendizaje profundo de atributos. La distribución original del rasgo morfológico se establece en la distribución normal. El modelo de aprendizaje de rasgos profundos predice si el valor de una característica morfológica es menor que eso \(\mu – \sigma\)Entre \(\mu – \sigma\) y + o superior \(\mu + \sigma\)dónde \(\mes\) Y el \(\sigma\) Consulte la media y la desviación estándar de la distribución del valor de la característica morfológica original.
Específicamente, para cada característica morfológica (p. ej., longitud de la glándula), la imagen de meibografía se envió a ResNet (una red neuronal de convolución residual de 18 capas)28 para obtener un vector de 64 dimensiones. El vector se proporcionó al agregar una capa completamente conectada inmediatamente después de la última capa de convolución de ResNet. Luego, el vector de características de 64 dimensiones se alimentó a otra capa completamente conectada para clasificar el atributo correspondiente (por ejemplo, el plano triple de la longitud de la glándula). El proceso fue el mismo para los ocho modelos de predicción de rasgos morfológicos, lo que significa que para cada imagen mimográfica había 8 vectores de 64 dimensiones, cada uno de los cuales denotaba el rasgo morfológico correspondiente.
Predecir la ventaja demográfica
En la segunda etapa, se desarrolló un modelo de aprendizaje profundo para predecir los rasgos demográficos de los miogramas y los rasgos correspondientes del modelo de aprendizaje de rasgos de la primera etapa (la segunda parte de la figura 3). En concreto, se ha introducido una determinada imagen en ResNet1828 para obtener un vector de 64 dimensiones. Se puede pensar en un vector como una inserción que codifica la información de la imagen. El vector se combinó con 8 vectores de rasgos morfológicos predichos del modelo de aprendizaje de rasgos profundos de la primera etapa. Todos los vectores tienen la misma dimensión. Los nueve vectores agregados en una capa convolucional completa se ingresaron para predecir características demográficas.
De las tres características demográficas que se pueden esperar, el género y la raza son categóricos, mientras que la edad es un número continuo. Después de Dana et al.29 Según la prevalencia del ojo seco, la edad del sujeto se dividió en tres categorías: (1) 39 años, (2) > 39, < 50 años y (3) ≥ 50 años.
El resultado final del modelo de predicción demográfica se puede explicar analizando los coeficientes adquiridos de las características morfológicas utilizadas para predecir las características demográficas. Los valores de coeficiente más altos indican una mayor ponderación de una característica morfológica en la predicción de una característica demográfica.
Escalas de calificación
El modelo se entrenó en el conjunto de entrenamiento utilizando hiperparámetros variables (p. ej., diferentes tasas de aprendizaje) y se seleccionó el modelo de mayor rendimiento en el conjunto de validación para la evaluación final sobre el conjunto de evaluación. Se seleccionaron los mejores modelos para el aprendizaje de rasgos y la predicción demográfica y se evaluaron según la precisión de su clasificación.
Calificación calificación con umbral de tolerancia
El método de evaluación se utilizó para evaluar el rendimiento del aprendizaje profundo de rasgos. Como se describió en la sección anterior, el modelo de aprendizaje profundo de rasgos de la primera etapa predice el nivel ternario de cada característica morfológica (o binario, en porcentaje de glándulas fantasma). Sin embargo, cerca del límite de transición para diferentes niveles (\(\mu – \sigma\) Y el \(\mu + \sigma\)), las características morfológicas pueden ser muy similares y difíciles de clasificar. Una técnica similar se describe en Wang et al.30 Se aplica aquí. Era necesario tener un límite de tolerancia cercano al límite de transmisión de grados. Como se muestra en la Figura 5, el umbral de tolerancia se fijó en 0,03\(\sigma\)y clasificar los valores de rasgos morfológicos dentro de ellos \(mu-1.06\sigma\) a mi \(\mu -0.94 \sigma\)Y el \(\mu +0.94 \sigma\) a mi \(mu+1.06\sigma\) Tanto en el nivel de verdad como en el nivel adyacente se tomaron como predicciones válidas. Tenga en cuenta que el umbral de tolerancia no se aplica a las predicciones porcentuales de glándulas fantasma, ya que se trata de una clasificación binaria.
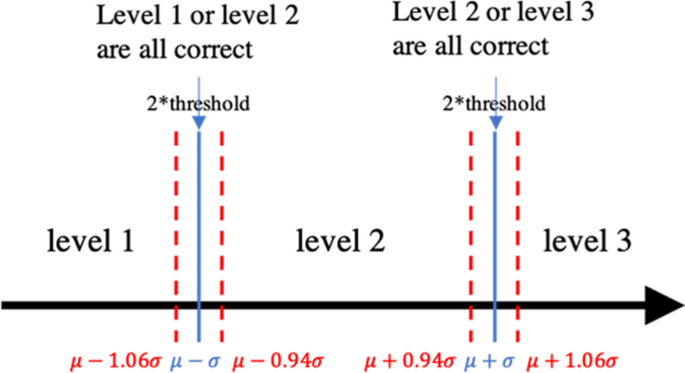
Base de evaluación para la clasificación de rasgos morfológicos confortables con umbral de tolerancia. El umbral de tolerancia se establece en 0,06\(\sigma\)y clasificar la imagen por porcentaje de atrofia \(mu-1.06\sigma\) a mi \(\mu -0.94 \sigma\)Y el \(\mu -0.06 \sigma\) a mi \(\mu +0.06 \sigma\)Y el \(\mu +0.94 \sigma\) a mi \(mu+1.06\sigma\) Ya sea a la verdad sobre el terreno o el plano adyacente se tomaron como predicciones válidas.
Validación cruzada quíntuple
Para evaluar tanto el aprendizaje de rasgos como el rendimiento de la predicción demográfica, así como informar la precisión de la clasificación en el conjunto de evaluación con el modelo de mejor rendimiento en el conjunto de validación, también se informó la precisión de la validación cruzada de cinco veces. Primero, todo el conjunto de datos (incluidos los subgrupos de desarrollo y evaluación) se dividió aleatoriamente en 5 partes. En segundo lugar, se realizaron 5 iteraciones de entrenamiento y evaluación. En cada iteración se utilizaron 4 pliegues para entrenamiento y el pliegue restante para evaluación. La media y la desviación estándar de la precisión de la clasificación en cada pliegue se informaron como una precisión de validación cruzada de cinco veces.

«Alborotador. Amante de la cerveza. Total aficionado al alcohol. Sutilmente encantador adicto a los zombis. Ninja de twitter de toda la vida».




More Stories
La Vía Láctea sobrevivió a una violenta batalla galáctica contra todo pronóstico científico
La NASA prueba helicópteros supersónicos para futuras misiones en Marte
La NASA descarta el impacto del asteroide 2024 YR4 contra la Luna en 2032